
多智能体系统(MAS)的概念在分布式计算领域已经存在数十年了。然而,大型语言模型(LLMs)和智能体人工智能的出现,使得智能体能够在以前无法实现的规模上进行推理、规划和协作。
一、多智能体架构
一个多智能体系统就是多个独立实体(智能体)的集合,这些实体通过协作——有时也通过竞争——来解决复杂问题。每个智能体都能够观察周围环境、做出决策并执行行动,且常常会与其他智能体展开协作。
这些系统不再仅存在于研究实验室中。它们出现在生产级应用程序中,例如:
• 自动研究助手能够读取、总结和交叉引用数据。
• 人工智能驱动的操作副驾驶可以监控基础设施、识别问题并发起变更。
• 自主交易系统能同时执行多种策略并交换研究结果。
• 多角色客户支持机器人会将咨询分配给专业的人工智能智能体,以实现更快的回复。
为什么智能体人工智能是变革性力量?
传统的多智能体系统设计需要硬编码逻辑、严格的程序和大量的手动设置。而智能体人工智能允许每个智能体利用以下能力:
•推理能力:大型语言模型可以容忍不明确的输入,仍然生成有意义的行动。
•情境感知:记忆系统使智能体能够从先前的交互中学习。
•智能体间通信:能让智能体动态地讨论它们的目标、限制和更新情况。
•自我改进循环:使智能体能够检查并根据自身表现进行调整 。
智能体人工智能的核心概念
在编写代码之前,你必须了解多智能体系统的基础知识。这些概念将影响你的架构设计、框架选择,以及在整个生产过程中智能体的交互方式。
- 智能体、自主性和目标:智能体是一个自包含单元,它能通过API、数据库、传感器数据等感知其环境;处理输入(进行推理、推断、决策);在环境中采取行动(触发工作流程、更新系统、进行通信)。自主性意味着智能体可以在没有人类持续监督的情况下运行。它们不会遵循固定的脚本,而是适应不断变化的输入;根据自身目标做出决策;从反馈循环中学习。
- 如何定义智能体?:让我们看看如何使用LangChain在Python中定义一个智能体。
from langchain.agents import initialize_agent, Tool from langchain.llms import OpenAI # 智能体的示例工具 def search_tool(query: str) -> str: return f"Searching for: {query}..." tools = [ Tool(name="Search", func=search_tool, description="Searches the web for information.") ] llm = OpenAI(temperature=0, api_key = "sk-projxxxxxxxxxxxxxxxxxxxx") agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True) agent.run("Find the latest AI research on multi-agent systems.")在进入创建这些强大智能体的下一个阶段之前,让我们先了解一下现有的多种智能体类型。
3.智能体类型:虽然所有智能体都有一个共同的目标,但它们的行动和思考方式有所不同。
| 类型 | 描述 | 适用场景 |
|---|---|---|
| 反应式智能体 | 直接对输入做出反应,无记忆或规划 | 诸如响应状态检查之类的简单任务 |
| 慎思式智能体 | 使用推理、规划,通常具有长期记忆 | 研究助手、决策机器人 |
| 混合式智能体 | 兼具反应式的速度和慎思式的推理能力 | 需要快速反应和规划的复杂工作流程 |
| 我的基本建议是:尝试使用混合式智能体,它完美融合了反应式和慎思式智能体的特点。混合式智能体在速度和灵活性之间取得了平衡,使其成为生产环境的最佳选择。 |
- 通信与协调:在实际生产中,智能体很少单独运行。通信策略包括智能体之间的直接API调用;消息队列(如RabbitMQ、Kafka、Pub/Sub)实现解耦和可扩展的协调;用于知识交换的共享内存存储库(例如Redis和向量数据库)。
- 记忆和长期情境管理:记忆将智能体从无状态函数转变为有状态的问题解决者。多智能体系统中的记忆类型包括:短期记忆为当前任务提供情境;长期记忆指的是在不同会话之间持久存在的知识;情景记忆——用于故障排除和学习的先前交互记录。让我们看看如何在智能体架构中初始化记忆。
from langchain.vectorstores import FAISS from langchain.embeddings.openai import OpenAIEmbeddings embeddings = OpenAIEmbeddings() memory_store = FAISS.from_texts(["Hello world", "Agentic AI is powerful"], embeddings) results = memory_store.similarity_search("Tell me about AI", k=1) print(results)这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
二、设计多智能体系统
构建一个适用于生产环境的多智能体系统,不仅仅是将大型语言模型的调用串联起来。从一开始,你就必须考虑职责划分、通信方式、容错能力、监控手段和可扩展性。
- 设计理念:模块化、可扩展、可互操作:在创建多智能体系统时,每个智能体都应该可以在不干扰系统其余部分的情况下进行替换;系统应该能够在不需要重新设计的情况下管理更多的智能体或任务;智能体应该使用通用的API或协议进行交互,以便于集成。建议做法:避免硬编码智能体依赖项。使用服务注册表或配置文件来指定可用的智能体。
- 定义智能体角色和职责:多智能体系统最关键的方面是为每个智能体明确职责,这可以避免职责重叠或冲突。
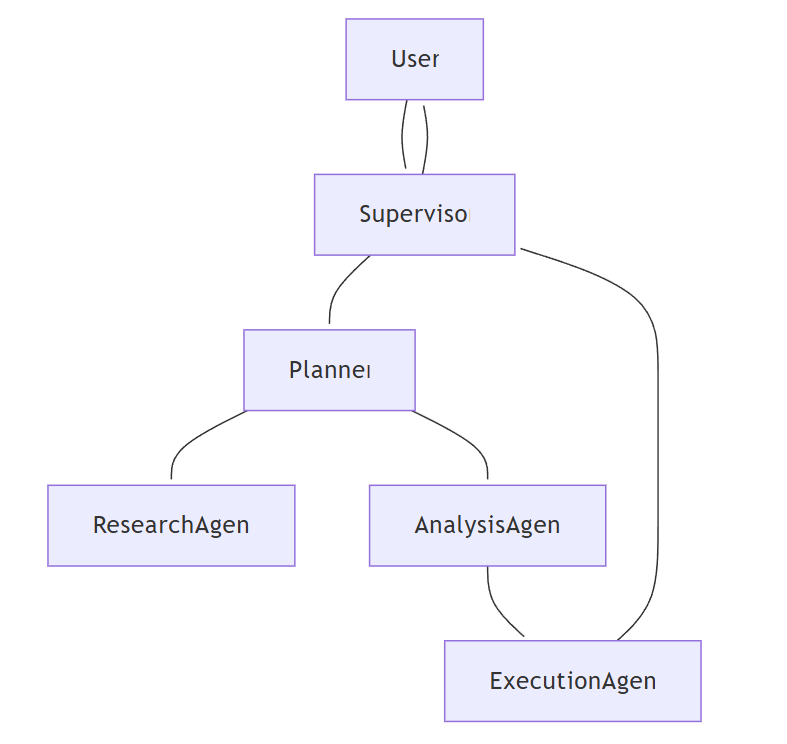
角色 职责 规划智能体 分解任务并分配给其他智能体 研究智能体 从API、数据库或网络收集数据 分析智能体 处理和解释收集到的数据 执行智能体 在实际系统中执行操作(例如部署代码、触发警报) 监督智能体 监控、验证输出并处理异常 以下是一个基于角色的智能体配置示例:
agents: planner: description: Breaks tasks into sub-tasks and delegates. tools: ["task_router", "status_tracker"] researcher: description: Finds and retrieves relevant information. tools: ["web_search", "api_fetch"] analyzer: description: Interprets and summarizes research findings. tools: ["nlp_analysis", "data_visualization"]- 选择通信协议:在生产环境中,智能体之间的通信方式对于速度、可靠性和规模至关重要。直接函数调用简单但智能体耦合紧密(适用于本地原型);消息代理(如RabbitMQ、Kafka、Pub/Sub)解耦、异步且可扩展;HTTP/gRPC API适用于在多个平台上运行并使用微服务的智能体;WebSocket提供实时双向通信。以下是通过Pub/Sub进行消息传递的示例:
import json from google.cloud import pubsub_v1 publisher = pubsub_v1.PublisherClient() topic_path = "projects/my-project/topics/agent-messages" message_data = json.dumps({"task": "fetch_data", "params": {"query": "AI news"}}).encode("utf-8") publisher.publish(topic_path, message_data)- 任务分解与编排:可以通过两种方式安排多智能体系统的编排。分层式——任务由中央控制器分配;去中心化——智能体围绕共同目标自组织。建议做法:分层式编排便于日志记录和调试,而去中心化编排在动态环境中表现更好。
工具、框架和技术栈
你所使用的工具将对多智能体系统产生重大影响。在生产环境中,正确的技术栈可确保系统的可扩展性、可维护性和成本管理。
- 智能体框架:框架可避免你在编排、消息传递和记忆处理方面重复造轮子。
框架 语言 优势 理想用例 LangChain Python/JS 工具集成、提示编排、记忆处理 快速构建复杂工作流程 AutoGen Python 多智能体聊天、智能体间消息传递便捷 对话式多智能体系统的快速原型开发 CrewAI Python 角色/任务分配、智能体协作 专注于任务的自治团队 OpenDevin Python DevOps和智能体编码自动化 人工智能辅助代码部署 AgentVerse Python 模拟、角色扮演智能体 研究和实验性多智能体系统 建议不要仅仅依赖于一个框架。你可以混合使用,例如,使用Langchain进行工具和记忆处理,使用AutoGen进行消息传递。
- 大型语言模型和基础模型:选择大型语言模型时要基于多种因素,包括成本、速度、可靠性和准确性。以下是一些可供参考的选择:
模型 优势 劣势 适用场景 GPT-4o 推理能力强、多模态 成本高、比小型模型慢 复杂规划智能体 Claude 3.5 Sonnet 总结能力强、输出安全 代码执行推理能力有限 研究和分析智能体 Mistral 7B 速度快、开源、成本低 深度推理能力较弱 高流量反应式智能体 LLaMA 3 70B 开源推理能力强 需要GPU基础设施 私有内部多智能体系统 对于生产需求,我强烈建议采用混合技术,例如可以使用像LLaMa 3.1 7B或Qwen 1B这样的小型模型进行过滤和分类;使用像GPT-5、GPT-4o系列、LLaMa 4系列这样的大型模型来处理复杂挑战。
- 记忆、向量存储和嵌入:智能体需要记忆才能在单个任务之外发挥作用。以下是一些常用的选择:FAISS是一个轻量级向量存储,完全在内存中运行;Chroma支持本地和云存储,与LangChain无缝连接;Weaviate可扩展、云原生,支持混合搜索;Pinecone托管式服务、速度快,但大规模使用可能成本较高。让我们看看如何使用Langchain处理记忆:
from langchain.embeddings.openai import OpenAIEmbeddings from langchain.vectorstores import FAISS embeddings = OpenAIEmbeddings() db = FAISS.from_texts(["Agentic AI is awesome", "Multi-agent systems scale work"], embeddings) print(db.similarity_search("Tell me about AI agents", k=1))- 通信中间件:通信层对于多智能体编排至关重要。以下是一些常见的选择:Pub/Sub(谷歌、Kafka)——异步且适用于大规模场景;Redis Streams——轻量级且速度快;WebSocket:实时双向通信;HTTP/gRPC与微服务可互操作。对于多云或混合系统,建议使用gRPC,它提供了可靠且高效的通信方式。
- 部署栈:在生产环境中,后端可使用FastAPI、Flask或Node.js作为API端点;使用Docker进行容器化以实现可移植性;使用Kubernetes进行智能体的扩展编排;使用Prometheus + Grafana或OpenTelemetry进行监控;使用GitHub Actions、Jenkins或GitLab CI进行持续集成/持续交付(CI/CD)。生产架构可能如下所示:
构建你的第一个多智能体系统
让我们看看如何开发一个包含三个智能体的系统。规划智能体负责将任务分解为子任务;研究智能体负责收集和整理信息;总结智能体负责为最终用户提炼研究结果。我们还将集成Pub/Sub消息传递进行通信;使用FAISS向量存储进行记忆处理;使用OpenAI GPT-4o进行推理。
- 步骤1——定义用例:我们将构建一个“研究与总结”多智能体系统:用户请求一个主题→规划智能体确定子主题→研究智能体收集信息→总结智能体将其浓缩为最终输出。
- 步骤2——选择智能体角色和提示:我们将角色和基本提示保存在YAML配置中,这样无需修改代码即可进行更新。
agents: planner: role: Break tasks into subtasks prompt: "Given a user query, list 3–5 research subtopics." researcher: role: Gather info for each subtopic prompt: "Search and retrieve concise, factual info on: {subtopic}" summarizer: role: Summarize all research prompt: "Summarize the following research into an easy-to-read format."- 步骤3——建立通信:这里我们使用谷歌的Sub/Pub进行异步消息传递。以下是使用发布者(向智能体发送任务)的示例:
import json from google.cloud import pubsub_v1 publisher = pubsub_v1.PublisherClient() topic_path = "projects/my-project/topics/agent-tasks" def send_task(agent, payload): data = json.dumps({"agent": agent, "payload": payload}).encode("utf-8") publisher.publish(topic_path, data)以下是订阅者接收信息(智能体接收任务)的方式:
from google.cloud import pubsub_v1 subscriber = pubsub_v1.SubscriberClient() subscription_path = "projects/my-project/subscriptions/planner-sub" def callback(message): print(f"Received task: {message.data}") message.ack() subscriber.subscribe(subscription_path, callback=callback)- 步骤4——实现任务路由和反馈:规划智能体将子任务发送给研究智能体,研究智能体将结果返回给总结智能体。智能体逻辑如下:
from langchain.llms import OpenAI llm = OpenAI(model="gpt-4o", temperature=0) def plan_research(query): prompt = f"Break this down into 3-5 subtopics: {query}" subtopics = llm.predict(prompt).split("\n") for topic in subtopics: send_task("researcher", {"subtopic": topic})- 步骤5——集成记忆:我们将使用FAISS为总结智能体存储检索到的研究内容。
from langchain.vectorstores import FAISS from langchain.embeddings.openai import OpenAIEmbeddings embeddings = OpenAIEmbeddings() db = FAISS.from_texts([], embeddings) def save_research(subtopic, text): db.add_texts([f"{subtopic}: {text}"]) def retrieve_all(): return "\n".join([doc.page_content for doc in db.similarity_search("", k=50)])- 步骤6——部署和测试:将每个智能体进行容器化,使其能够独立运行;使用Kubernetes根据负载扩展研究智能体;设置日志记录(例如Stackdriver、ELK Stack)以跟踪消息流;监控Pub/Sub延迟和FAISS搜索性能。Dockerfile内容如下:
FROM python:3.11 WORKDIR /app COPY . /app RUN pip install -r requirements.txt CMD ["python", "agent.py"]三、结论:从蓝图到生产
多智能体系统不再仅仅是学术概念——它们正在成为下一代人工智能应用的支柱。通过结合大型语言模型进行推理、明确的智能体角色分工、强大的通信渠道和可扩展的部署栈,开发者可以构建出真正能够实时协作和自适应的生产级系统。
在本文中,我们探讨了自主性、智能体类型、记忆和通信的核心概念;确保模块化、可扩展性和互操作性的架构原则;加速开发的实用框架和技术栈;一个从YAML配置到Pub/Sub消息传递、FAISS记忆处理和容器化部署的研究与总结多智能体系统的实践实现。
核心要点很简单:多智能体设计并非过多涉及复杂理论,而更多在于深思熟虑的工程选择。从小处着手(比如我们构建的三智能体系统),衡量性能,然后通过更多专业智能体、通信层和编排策略进行迭代。
接下来你可以做什么:
• 尝试不同的框架(如LangChain、AutoGen、CrewAI)并比较权衡。
• 为你的多智能体系统引入监控和自我改进循环以增强稳健性。
• 通过引入Kubernetes、gRPC和高级内存存储逐步扩展到生产环境。
智能体人工智能的时代才刚刚开始——通过了解如何设计、协调和扩展这些系统,你正在为未来最强大的应用程序奠定基础。
四、如何学习AI大模型?
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!
第一阶段:从大模型系统设计入手,讲解大模型的主要方法;
第二阶段:在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段:大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段:大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段:大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段:以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段:以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案
大模型全套视频教程
200本大模型PDF书籍
👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集
大模型产品经理资源合集
大模型项目实战合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓





