
Markdown水平线分割不同PyTorch章节内容
在构建深度学习开发环境时,我们常常面临两个看似不相关的挑战:一是如何快速部署一个稳定、可复用的训练环境;二是如何让技术文档清晰易读,帮助团队成员高效获取关键信息。前者关乎工程效率,后者影响知识传递——而当我们将二者结合,就会发现,真正的AI工程化不仅在于代码和模型,更体现在整个工作流的系统性设计。
以 PyTorch-CUDA 镜像为例,它本质上是一个容器化的深度学习运行时,集成了特定版本的 PyTorch 框架与 NVIDIA CUDA 工具链。这类镜像通常基于 Ubuntu 等 Linux 发行版构建,通过 Docker 或 Kubernetes 实现跨平台部署。它的核心价值在于“开箱即用”:开发者无需再为torch.cuda.is_available()返回False而排查驱动兼容性问题,也不必手动安装 cuDNN、NCCL 等底层库。只需一条命令拉取镜像,即可进入 Jupyter Notebook 或 SSH 终端开始实验。
import torch if torch.cuda.is_available(): print("CUDA is available!") print(f"GPU count: {torch.cuda.device_count()}") print(f"Current GPU: {torch.cuda.get_device_name(torch.cuda.current_device())}") x = torch.randn(3, 3).to('cuda') print("Tensor on GPU:", x) else: print("CUDA not available. Running on CPU.")这段验证代码几乎成了每个使用 PyTorch-CUDA 镜像后的“仪式感”操作。它简单却关键——确认 GPU 是否被正确识别,是后续所有训练任务的前提。而在实际项目中,这样的环境一旦配置完成,往往需要通过文档形式固化下来,供团队共享或新人参考。
这时就引出了另一个常被忽视的问题:技术文档的结构是否足够清晰?
设想你正在查看一份镜像使用说明,内容依次包括简介、Jupyter 使用方式、SSH 接入方法、环境变量配置等模块。如果这些部分只是靠标题和空行分隔,读者很容易产生视觉疲劳,尤其是在图文混排的情况下。图片下方的文字可能被误认为属于前一节,导致理解偏差。这时候,一个简单的---就能起到“视觉锚点”的作用。
Markdown 中的水平线(Horizontal Rule)语法极为简洁:
--- *** ___这三种写法都会被解析为 HTML 中的<hr>标签,在 GitHub、GitLab、Jupyter Notebook 等主流平台中渲染为一条横贯页面的分隔线。虽然它本身没有语义含义,也不参与文档大纲生成,但其视觉引导能力极强。尤其在长篇技术文档中,合理使用水平线能让读者自然感知到“当前模块结束,下一阶段开始”。
比如在一个典型的 PyTorch 开发镜像文档中,可以这样组织:
# PyTorch-CUDA-v2.7镜像 ## 简单介绍 版本号:PyTorch-v2.7 PyTorch-CUDA 基础镜像是一个开箱即用的深度学习环境... --- ## 使用说明 ### 1、Jupyter的使用方式  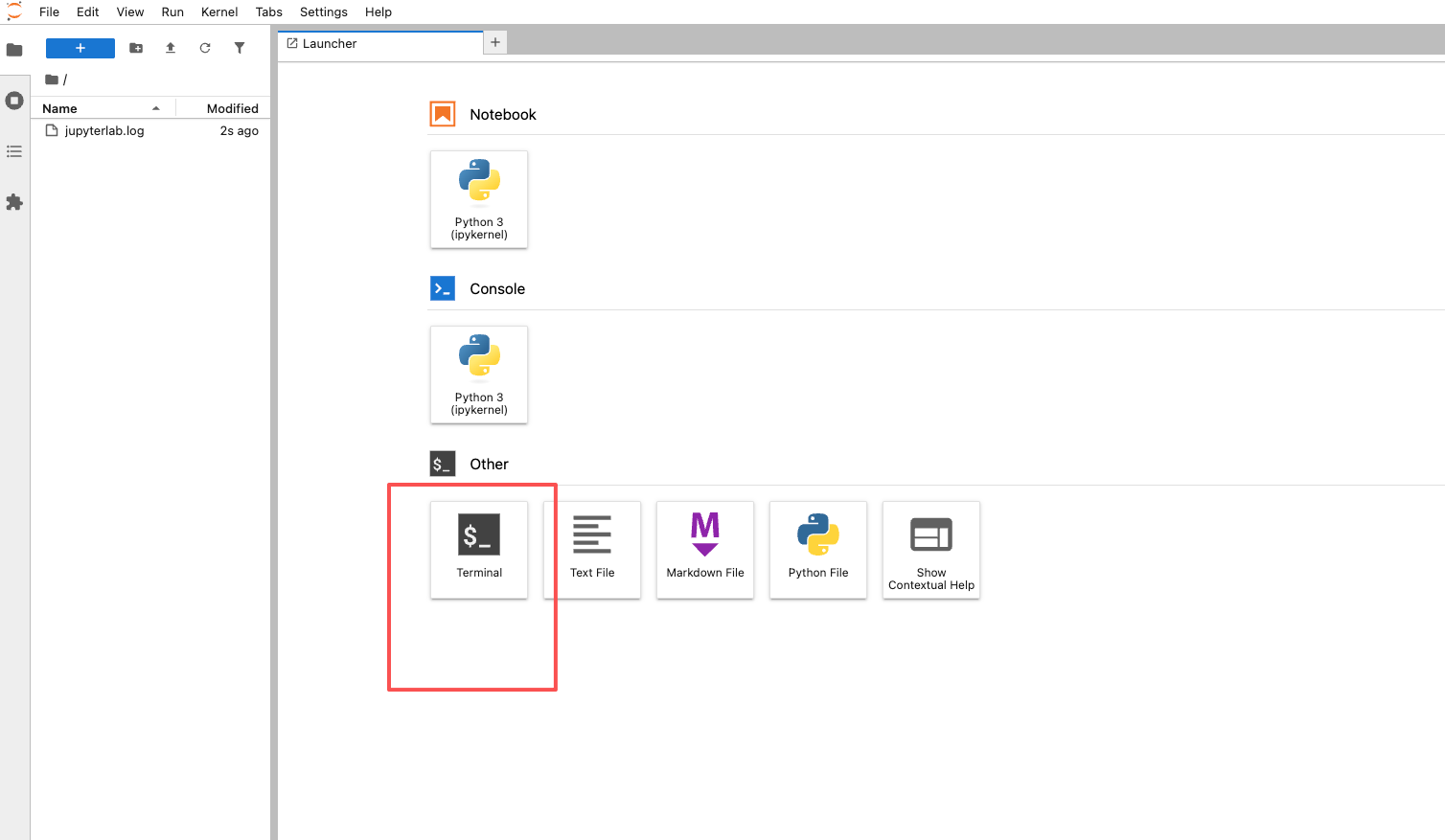 --- ### 2、ssh的使用方式  这里的每一条---都不是随意添加的。第一条位于“简单介绍”与“使用说明”之间,标志着从“是什么”转向“怎么用”;第二条则明确区分了两种并列的接入方式——Jupyter 和 SSH。它们互不依赖,用户可以根据需求选择其一,因此用水平线而非子标题来分隔更为恰当。
这种结构化思维其实对应着系统的分层架构:
+-----------------------+ | 应用交互层 | | - Jupyter Notebook | | - SSH 终端接入 | +-----------------------+ | 深度学习运行时层 | | - PyTorch (v2.7) | | - TorchVision/Torchaudio | +-----------------------+ | GPU 计算支持层 | | - CUDA Toolkit | | - cuDNN / NCCL | +-----------------------+ | 容器与硬件层 | | - Docker / Kubernetes| | - NVIDIA GPU Driver | +-----------------------+每一层都依赖下一层提供支持,而文档的结构也应反映这种层次关系。水平线的作用,正是将抽象的系统架构转化为具体的阅读体验:当你滑动页面看到一条横线时,潜意识里已经准备好迎接新的功能模块。
当然,任何工具都有其最佳使用边界。水平线虽好,但也需注意几点实践原则:
- 数量控制:一页文档内建议不超过 3~5 条,过多会割裂内容,造成“碎片化”错觉;
- 位置精准:应放在逻辑单元结束后、新单元开始前,配合前后空行使分隔更自然;
- 风格统一:全文档统一使用
---或***,避免混用降低专业感; - 不可替代标题:它不能取代
##或###的结构性作用,仅作为视觉补充。
从工程角度看,PyTorch-CUDA 镜像解决了环境一致性难题,而 Markdown 水平线则提升了文档的认知效率。两者看似层级不同,实则共同服务于同一个目标:降低协作成本。
试想一个新成员加入项目,他拿到的不只是一个能跑通代码的镜像,还有一份结构清晰、重点突出的使用手册。他可以迅速判断:“哦,这部分讲的是远程接入方式,我只需要看 SSH 这块。” 而不需要逐行扫描文字去猜测段落归属。这种流畅的上手体验,往往决定了项目的初期推进速度。
更重要的是,这种规范容易复制。一旦形成模板,就可以推广到其他框架(如 TensorFlow、HuggingFace)的文档编写中,甚至集成进 CI/CD 流程,实现自动化文档生成。例如,利用 MkDocs 或 Docsify 构建静态站点时,预设的分隔规则能让输出内容始终保持一致的排版风格。
回到最初的那个问题:为什么要在一篇关于 PyTorch 镜像的文章里讨论 Markdown 水平线?
答案是:优秀的工程技术从来不只是“能用”,而是“好用且易传播”。一个再强大的环境,如果文档混乱,依然会造成大量重复沟通;反之,一个结构清晰的文档,哪怕只是用几个---分隔,也能显著提升团队的整体效率。
这也正是现代 AI 工程实践的趋势所在——我们不再满足于“跑通一个模型”,而是追求端到端的标准化:从环境构建、代码管理,到文档撰写、知识沉淀。每一个细节都在累积系统的可靠性。
所以,下次你在写技术文档时,不妨停下来问一句:这里是不是该加一条---?也许就是这个小小的决定,让别人少花十分钟摸索,多出一次高效的协作。





